Services
Global institutions trust Ona to support their critical work with our products and dynamic team of experts. We collaborate on building and implementing solutions to pressing needs — making data visible to effect change.
Modern data stack as a service
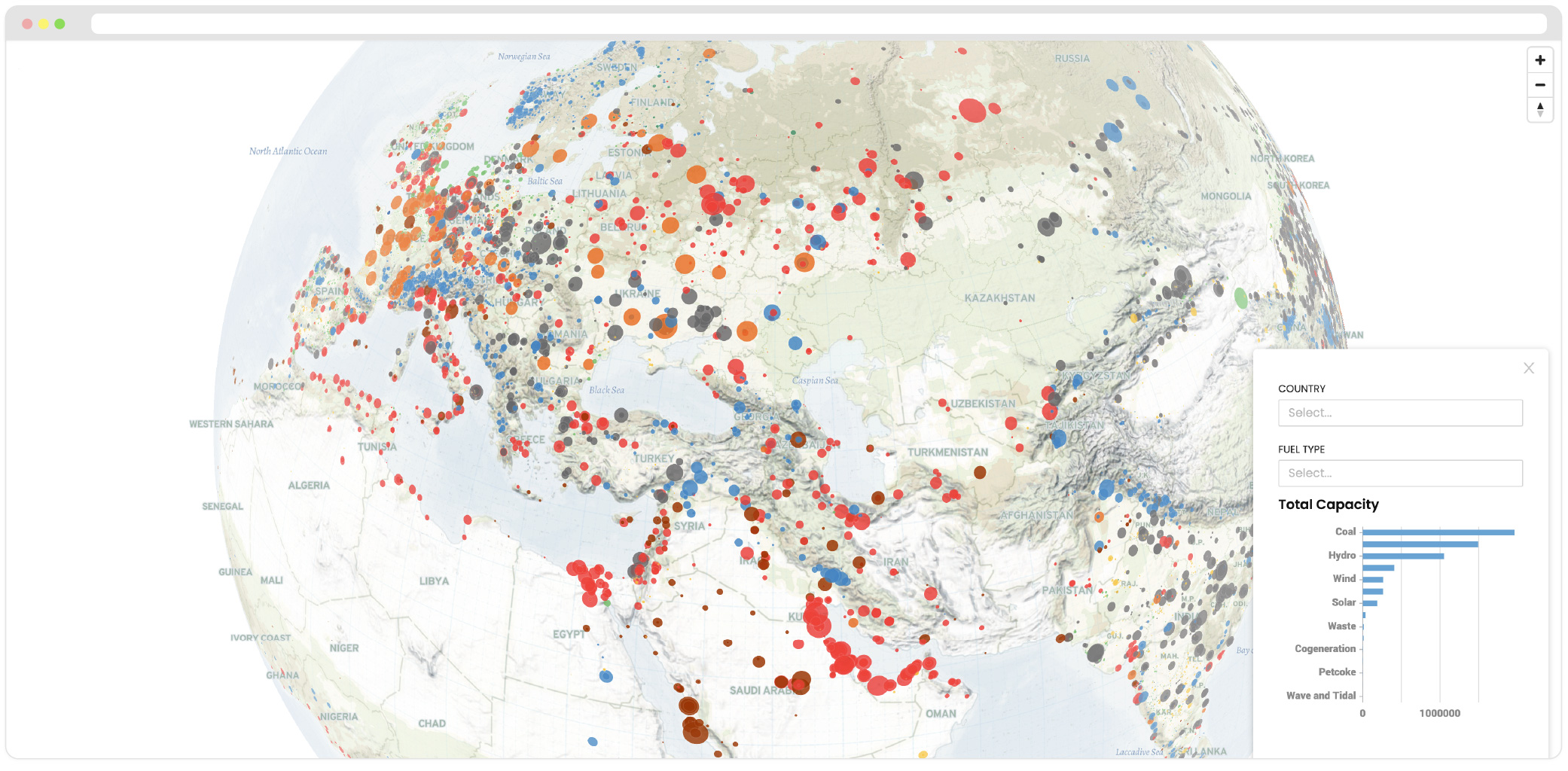
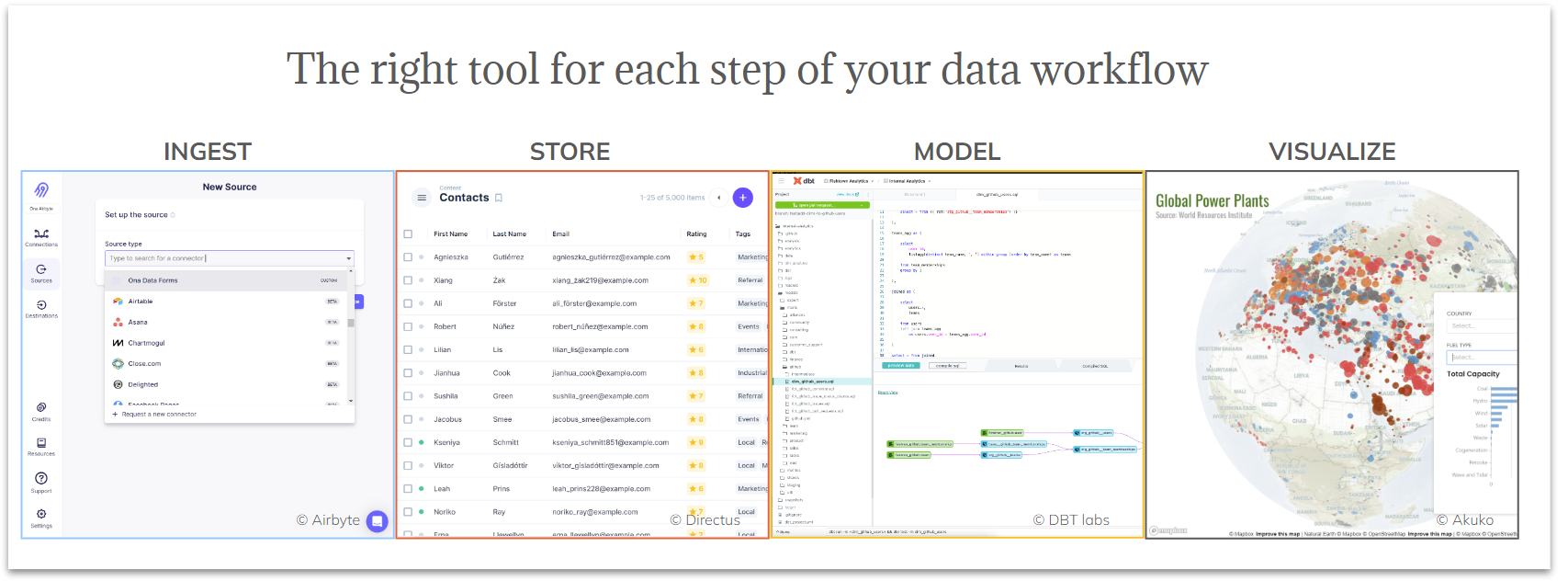
Canopy is a data analytics service for development organizations, combining best-of-breed tools and relevant support to help you manage and utilize your data.
Collecting data is not enough, it must be integrated and understood to generate value. Canopy is Ona’s service to help you organize, store, and analyze your data, taking advantage of the modern data stack. We provide you with best-of-breed technologies and take care of the hosting, so you can focus on driving insights for your project outcomes.
The modern data stack, for development
Every organization has different data needs. Instead of relying on a single inflexible application, the modern data stack is a collection of tools to achieve end-to-end analytics: ingestion, transformation from centralized storage, business intelligence and geospatial analysis. Ona has selected the best tools for the needs of social impact and international development organizations and made them available to partners as a managed service through Canopy.
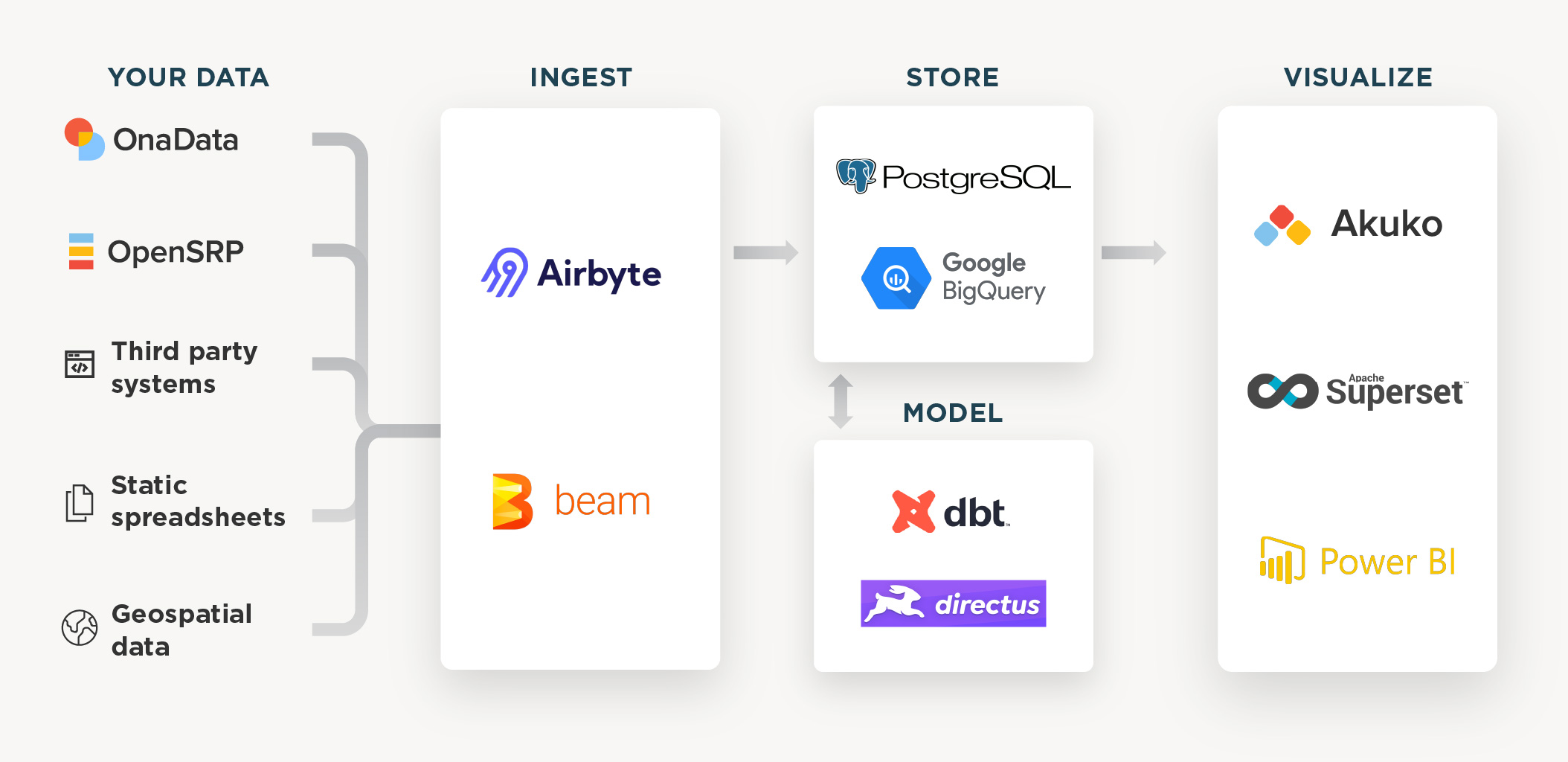
What you can expect from the package
Canopy is a customized service. Ona will assist you in understanding the tools that are best suited for your needs, most of which are open-source. In general, you can expect the following:
A data ingestion tool. Create near-real-time integrations from a list of supported sources and monitor the status of connectors over time (additional sources can be added as part of our data services).
A scalable data warehouse. Store all your data in one place and break the silos of different data sources.
A modeling and/or content management tool. Normalize, clean, and join data from your various sources, preparing it for analysis. Use a clickable user interface or a scripting tool for the best results based on your technical requirements.
A powerful data visualization tool. Analyze your data and share your insights using Business Intelligence software, for example Ona’s Akuko platform.
Onboarding advisory and support. Our experienced team will help you get started with the tools and be available if you are blocked, with a dedicated support package based on the technical skills available within your organization.
A hassle free experience with easy handover
Canopy is designed to help organizations better manage and make use of their data. This can be as simple initially as wanting to integrate several real time forms into a dashboard to combining multiple realtime data systems into a single organizational view. With Canopy we offer you a simple package for hosting the modern-data-stack, combined with the capacity building required to manage them. At the end of the service period, most tools are transferable and deployable on-premise.

Use Canopy to power your solution
As part of our analytics services, Ona can support you in the design, implementation, and handover of a custom information system that is tailored to the needs of your project. Moreover, we provide capacity building for your teams to understand the technologies and the best practices in data management. Do you need to integrate custom data sources, use different data visualization components, or create fully usable tools and applications for your stakeholders? You can use Canopy as part of a dedicated solution.
